Why Website Reliability Is a Marketing Problem, Not Just an Engineering Problem
A reliable website protects the attention, trust, and revenue that marketing worked hard to earn.
A reliable website protects the attention, trust, and revenue that marketing worked hard to earn.
Reliability is often treated as something that belongs to engineering.
That is understandable. Engineers choose hosting platforms, configure deployments, monitor uptime, tune databases, manage DNS, handle incidents, and recover from failures. When something breaks, engineering is usually the team with hands on the keyboard.
But visitors do not experience reliability as an engineering issue.
They experience it as a brand issue.
A page that will not load, a form that fails silently, a checkout flow that times out, a DNS error after clicking a campaign link, or a slow landing page during a product launch all communicate something about the business. The visitor may not know whether the cause was a bad cache rule, a third-party script, a database connection pool, a failed deployment, or an overloaded origin.
They only know the experience did not work.
That is why website reliability is a marketing problem too. Marketing creates demand, earns attention, and persuades people to take the next step. Reliability determines whether that attention survives contact with the website.
Reliability Protects Earned Attention
Every serious marketing effort has a cost. Paid search has a cost. Social campaigns have a cost. Content production has a cost. Sales outreach has a cost. Brand building has a cost. Even organic traffic is not free; it is the result of years of publishing, reputation, technical SEO, and useful work.
When the website fails, that investment leaks away.
A campaign can have the right audience, the right offer, and the right message, then underperform because the landing experience is slow, unstable, or confusing during the moment of intent. The marketing team may see lower conversion rates, higher bounce rates, weaker lead quality, or unexplained attribution gaps. The root cause may look like messaging, creative, or channel quality. Sometimes it is reliability.
The visitor who clicks a link from an ad is giving the business a small amount of attention. That attention is fragile. If the page hangs for five seconds, shifts around while loading, throws a certificate warning, or renders a broken form, the visitor has already learned something. They have learned that the business may not be as operationally sharp as the campaign suggested.
Reliability preserves the gap between interest and action. It keeps the visitor in the decision path long enough for the content, offer, and design to do their job.
Most Reliability Damage Is Quiet
Major outages are obvious. The site is down. Forms stop working. Sales complains. Support tickets appear. Someone opens an incident channel. The business knows there is a problem.
The quieter failures are more dangerous because they often go unnoticed.
A third-party script slows one page type on mobile. A DNS change creates intermittent resolution issues in one region. A misconfigured cache serves stale campaign copy. A form provider accepts the submission but drops the CRM integration. An image transformation service times out for large hero images. A tag manager update blocks the main thread. A cookie consent banner breaks a CTA on small screens. A CDN rule redirects a paid campaign URL to the wrong page.
None of these failures necessarily look like a full outage.
They look like lower performance.
They look like fewer leads.
They look like campaign fatigue.
They look like visitors not being ready.
This is why marketing and engineering need a shared language for reliability. If the only signal is whether the homepage returns a 200 status code, the business is blind to many of the failures that actually affect revenue.
Uptime Is Not Enough
Uptime matters, but it is a blunt measure.
A website can be technically up and still fail the user. A page can return successfully and still take too long to become useful. A form can render and still fail after submission. A checkout can load and still break when a payment provider is slow. A CMS can publish and still invalidate the wrong cache. A search engine can crawl the page and still see a version users never experience.
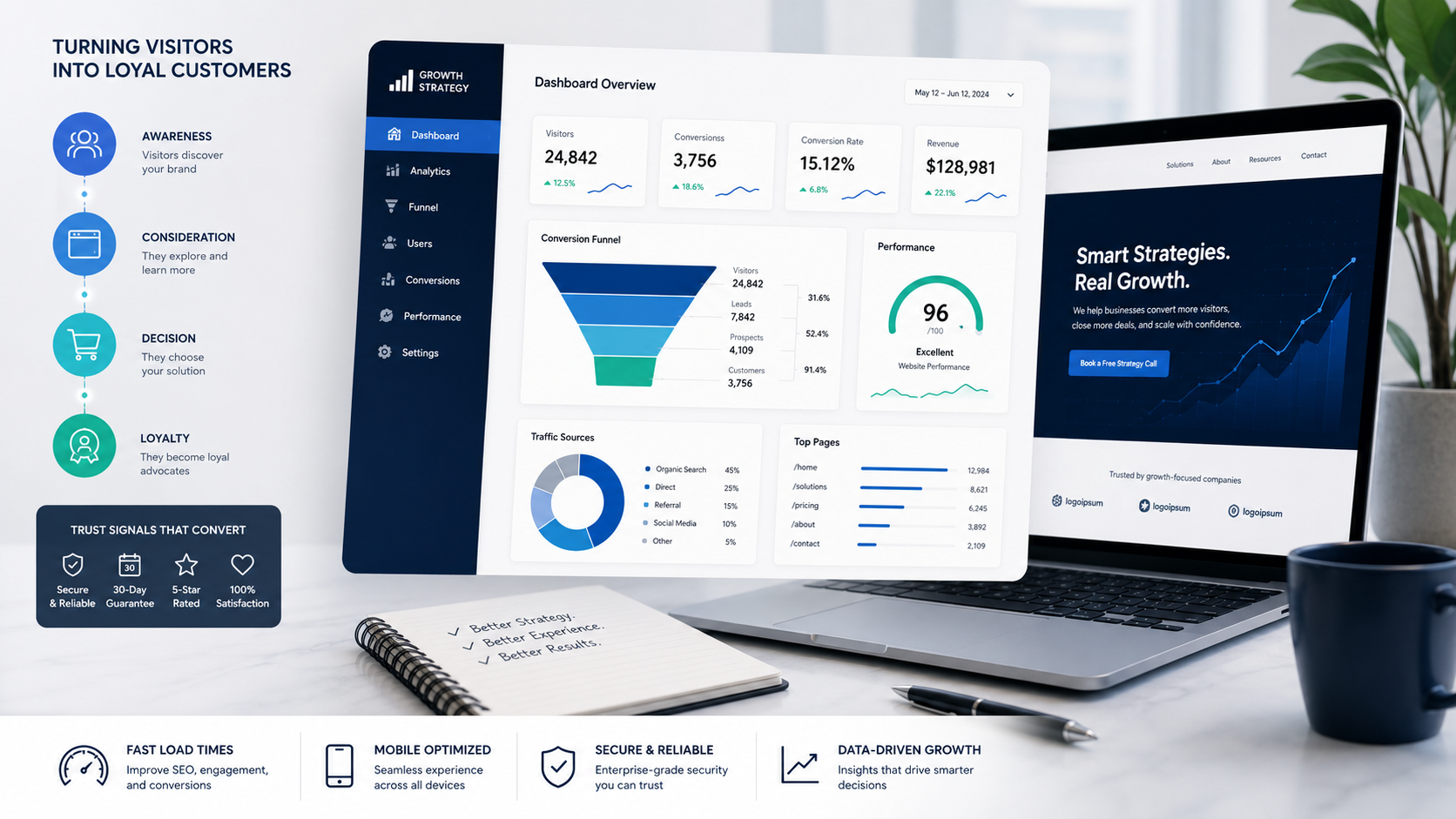
Marketing needs reliability measured closer to the visitor journey.
Can users reach important pages? Can they complete key forms? Are landing pages fast in the regions where campaigns are running? Are Core Web Vitals stable after a release? Are redirects correct? Are tracking parameters preserved? Are thank-you pages firing the expected analytics events? Are broken images or JavaScript errors concentrated on high-value pages?
These are reliability questions.
They are also marketing questions.
A useful reliability practice should monitor not only infrastructure health, but user-path health. The homepage matters, but so do service pages, pricing pages, campaign landing pages, blog posts that rank, contact forms, booking flows, newsletter forms, login pages, checkout steps, and confirmation screens.
The Funnel Has Technical Failure Modes
Marketing funnels are usually drawn as behavioral systems: awareness, consideration, decision, conversion, retention. That is useful, but incomplete.
Every funnel also has technical failure modes.
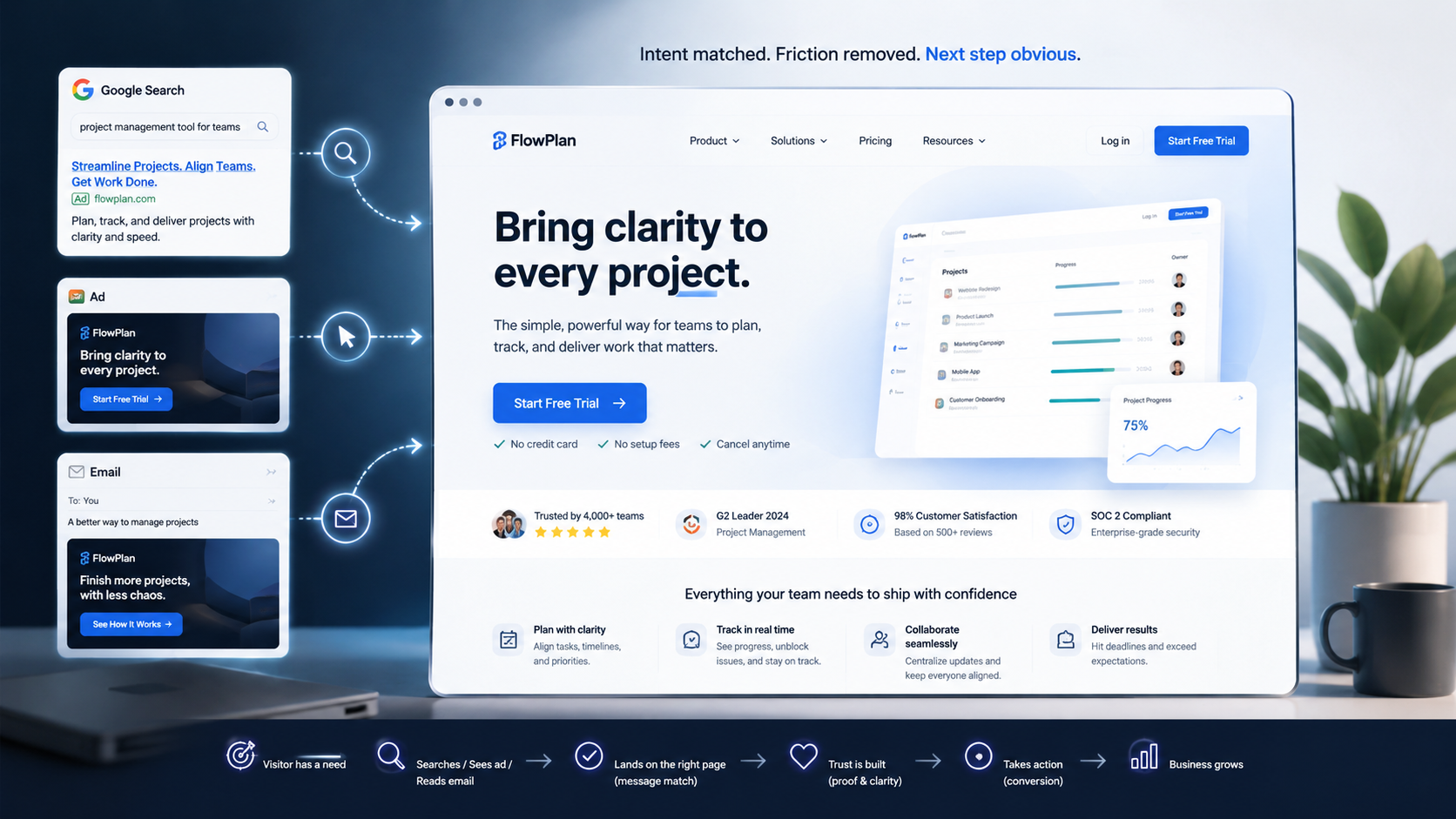
At awareness, DNS, redirects, page speed, and social preview metadata affect whether the first click lands cleanly.
At consideration, content delivery, image performance, navigation, search indexing, and mobile rendering affect whether the visitor can evaluate the offer.
At decision, forms, booking widgets, pricing pages, comparison pages, consent tools, CRM integrations, and analytics events affect whether action is captured correctly.
After conversion, confirmation emails, routing logic, lead enrichment, sales notifications, and support handoffs affect whether momentum continues.
A funnel is not only copy and design. It is a chain of dependencies.
That chain includes the browser, DNS provider, CDN, hosting platform, frontend framework, backend APIs, CMS, form vendor, CRM, analytics stack, tag manager, consent system, email service, and sometimes payment infrastructure.
The more important the website becomes to the business, the more important it is to understand this chain.
Reliability Is Also a Trust Signal
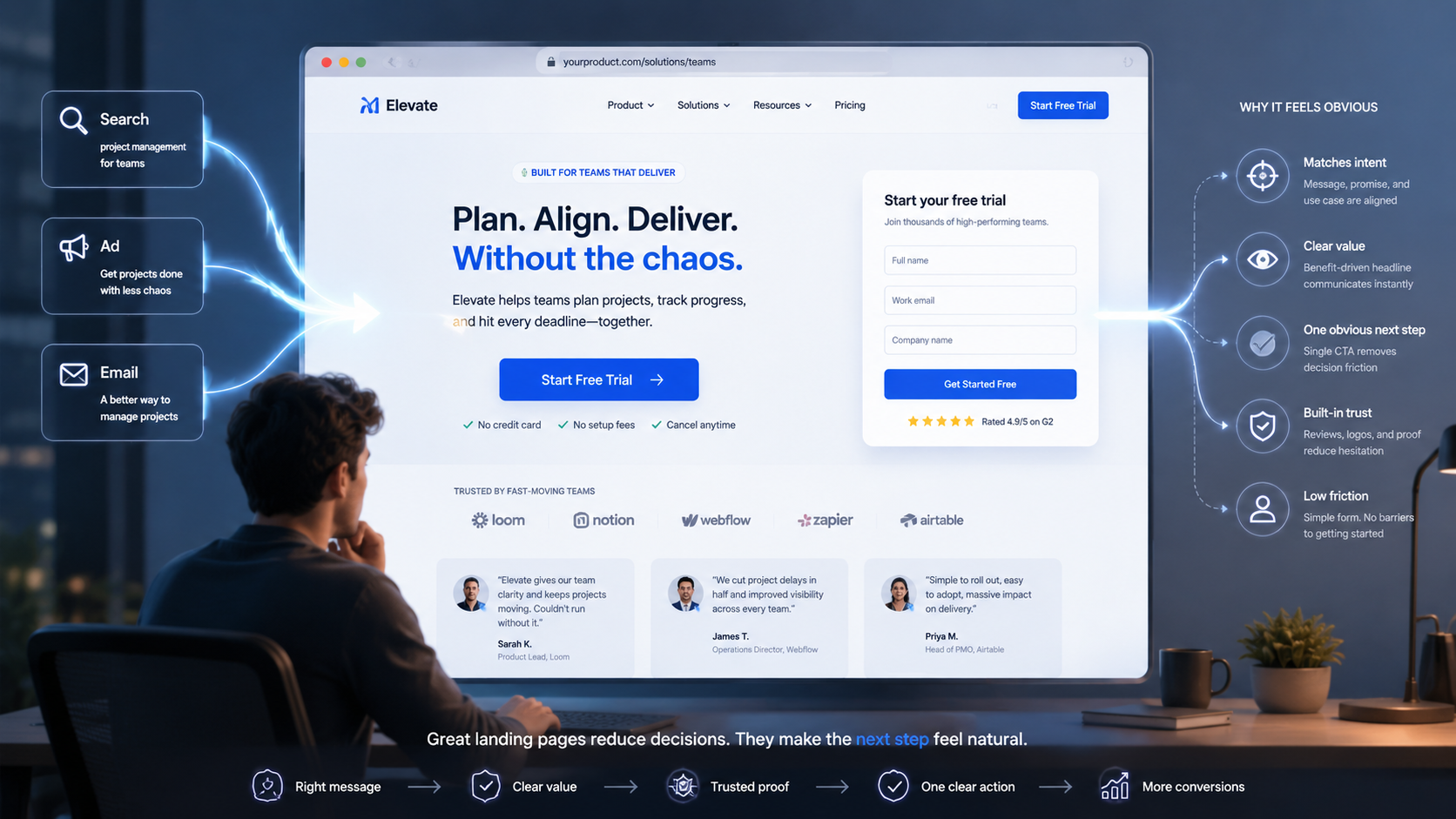
People infer competence from digital experiences.
They may not say it directly, but they feel it. A fast, stable site feels like the business has its act together. A slow or broken site creates doubt. This is especially true for companies selling technical, strategic, financial, legal, healthcare, or professional services where buyers are already evaluating risk.
A reliability problem can undercut trust before a salesperson ever speaks to the prospect.
If a cloud consulting company has a slow, fragile website, buyers notice the contradiction. If a cybersecurity firm has mixed-content warnings, broken forms, or outdated dependencies causing visible errors, the website quietly weakens the claim of operational maturity. If a managed services provider cannot keep its own booking flow working, a prospect may wonder how carefully the provider will manage client systems.
The website is part of the proof.
Reliability does not guarantee trust, but unreliability can destroy it quickly.
Incident Planning Should Include Marketing
Many incident response plans focus on technical restoration. That is necessary, but marketing should be part of the plan when the website is a meaningful revenue channel.
If a campaign landing page breaks during a launch, who pauses spend? Who updates stakeholders? Who checks whether traffic should be routed to a fallback page? Who confirms whether analytics data can be trusted? Who communicates with sales if leads were lost or delayed? Who verifies that the fix restored the full conversion path, not just the server response?
These questions should be answered before the incident.
A practical plan does not need to be elaborate. It should define severity levels, communication channels, ownership, rollback paths, fallback pages, contact lists, and post-incident review steps. It should also identify high-value pages and flows so the team knows what to protect first.
A small business does not need enterprise theater. It needs clear ownership and a recovery path.
The most expensive moment to decide who owns a website incident is during the incident.
Observability Should Follow Business Value
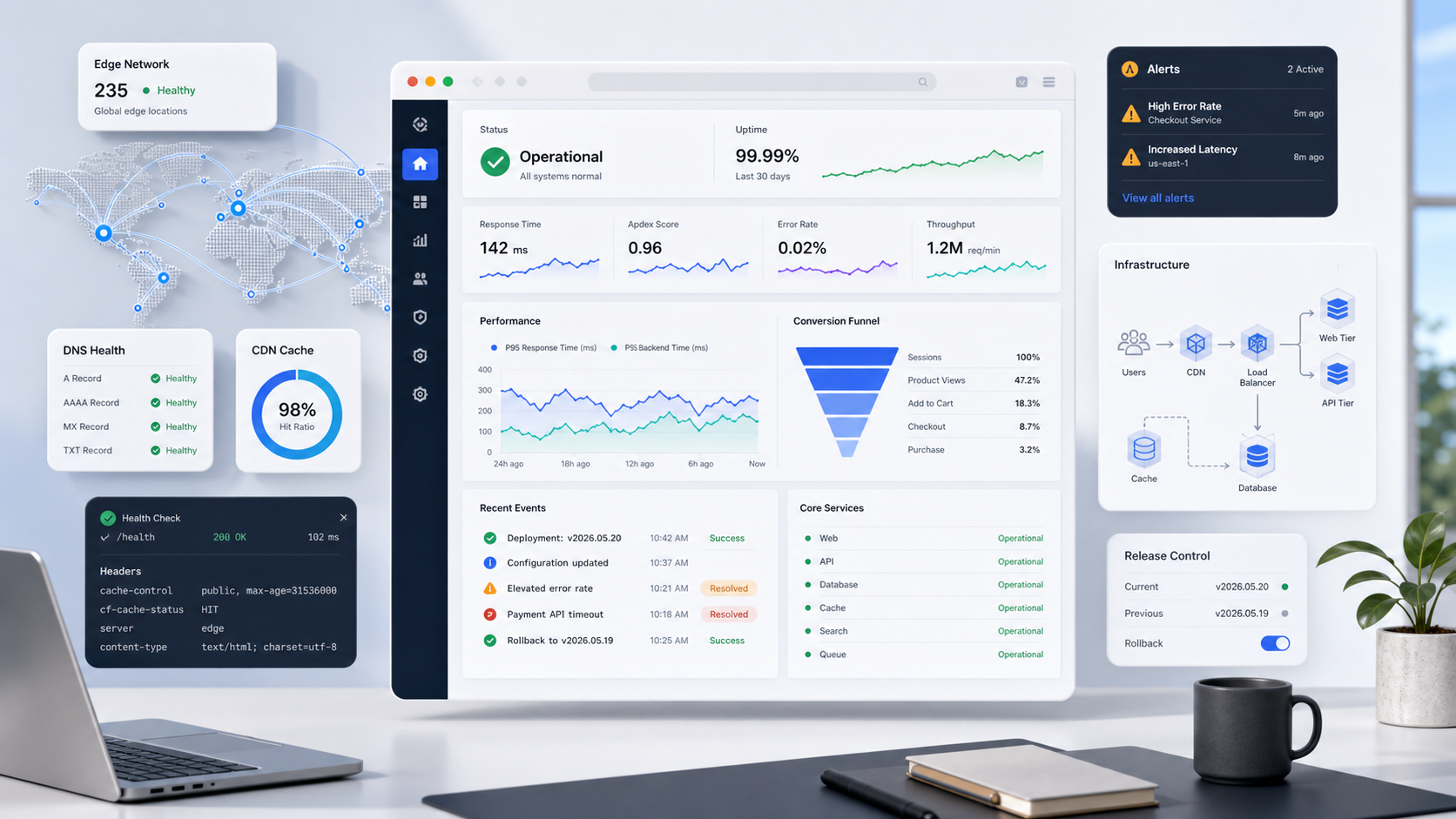
Observability is often built around infrastructure metrics: CPU, memory, request count, error rate, latency, logs, and traces. Those signals matter, but they need context.
For a marketing website, the most important question is not only, 'Are systems healthy?' It is, 'Can visitors do the valuable things we need them to do?'
That means monitoring should include synthetic checks for important pages and flows, real user monitoring for performance, error tracking for browser exceptions, form submission monitoring, analytics validation, uptime checks from relevant regions, and alerting tied to business-critical paths.
A service page that gets 200 visits a month may not need the same monitoring as a campaign page receiving paid traffic. A blog post ranking for a valuable query may deserve a faster response than an obscure archive page. The contact form is more important than a decorative animation.
Good observability helps teams prioritize.
It also prevents arguments based on anecdotes. Instead of guessing whether the site 'felt slow' or whether 'leads seemed down,' the team can inspect real data: page load distributions, error rates, failed submissions, broken routes, latency by region, and conversion impact.
Reliability Requires Boring Discipline
The best reliability work is often unglamorous.
Keep DNS documented. Use a CDN. Cache static assets correctly. Test redirects. Maintain a rollback path. Monitor key pages. Keep dependencies patched. Reduce third-party script weight. Compress images. Use health checks. Back up content. Verify form routing. Test mobile. Review certificate expiration. Separate preview and production. Avoid manual launch rituals. Keep credentials out of code. Make deployments repeatable.
None of that sounds like a campaign idea.
But it protects campaigns.
Reliability is not achieved by one heroic launch-day effort. It is built through repeatable habits that reduce surprise. This is why mature teams prefer boring infrastructure decisions, clear ownership, and simple recovery paths over fragile cleverness.
A website does not need an over-engineered architecture to be reliable. It needs an architecture the team understands, can monitor, and can recover.
What Marketing Should Ask Engineering
Marketing teams do not need to become infrastructure engineers, but they should know which questions to ask.
What are the most important pages and flows from a revenue perspective? Are they monitored? What happens if a deploy breaks one of them? How quickly can we roll back? Are form submissions tested end to end? Are analytics events validated after changes? Are campaign redirects owned somewhere visible? Are landing pages cached correctly? Are third-party scripts reviewed before they are added? Are we measuring real user performance or only lab scores? Do we know which regions and devices our visitors actually use?
These questions create alignment.
They also make reliability less abstract. Instead of discussing uptime in isolation, the team discusses business paths: contact, booking, purchase, signup, trial, download, demo request, newsletter subscription, application, or support request.
When marketing and engineering share that map, the website becomes easier to operate.
Final Thought
Website reliability is not just an engineering concern because visitors do not separate engineering from brand experience.
When the site works, marketing gets the chance to persuade.
When the site fails, the business may lose the visitor before persuasion begins.
Reliability protects attention. It preserves trust. It keeps campaigns from wasting spend. It helps analytics remain credible. It gives sales better handoffs. It makes the website feel like a competent part of the business rather than a fragile brochure.
The goal is not perfection. Perfect uptime is not a strategy.
The goal is operational maturity: know what matters, monitor the paths that create value, recover quickly, and treat reliability as part of the customer experience.
A website that is reliable is not merely online.
It is ready when the buyer is.